Débuter en growth outbound : j’ai appris à cibler, scraper et enrichir mes leads
Apprenez à scraper, cibler et enrichir vos leads B2B quand vous débutez en growth outbound. Cas pratiques à l’appui.

Sommaire
le meilleur ici 👇
Vous avez déjà cherché comment apprendre le scraping ou le ciblage de données B2B quand on débute ?
Entre les tutos obscurs, les formations hors de prix et les promesses miracles, difficile de savoir par où commencer, surtout quand on vient du marketing “classique”.
Moi, je voulais du concret. Comprendre comment fonctionne cette stratégie marketing, mettre en place une campagne d’outreach de A à Z, tester des outils, créer mes propres séquences, et voir si j’étais capable de le faire… sans background tech, sans code, mais avec méthode.
Alors j’ai testé. Une formation ultra ciblée, des outils no-code en version freemium, et une vraie mise en pratique pour construire une base de leads, la scraper, l’enrichir… et surtout la rendre activable.
Je vous raconte tout.
Ce que j’ai appris, ce qui a marché, ce qui m’a frustrée et comment vous pouvez faire pareil, pas à pas.
Mon besoin initial : découvrir l’outreach marketing
Quand on tape ‘formation growth hacking’ sur Google, on tombe sur tout et n’importe quoi. Moi, j’avais besoin de concret. Comprendre comment fonctionne une campagne d’outreach marketing.
Avant de me lancer, tête baissée dans des formations onéreuses ou de postuler à différents postes, j’avais pour objectif de toucher à tout et de me faire une première idée de la diversité des stratégies marketing et métiers du Growth.
Il y a en un qui m’intriguait particulièrement car je ne l’avais jamais appliqué dans mon expérience de marketeuse traditionnelle : le Growth Outbound.
Et puis, c’est aussi le profil le plus répandu dans l’écosystème : accessible aux juniors, exposé très tôt à des tests variés, et surtout… la première brique de toute stratégie d’acquisition digne de ce nom. Bref, j’avais intérêt à découvrir toutes les facettes de ce métier.
Et surtout, si j’étais capable de le faire, avec mes compétences de communicante “traditionnelle” en bagage.
Premier constat : que l’on soit marketeux tradi confirmé, solopreneur débordé ou en reconversion comme moi, il y a fort à parier que cette partie-là vous semble floue.
Ce métier n’est quasiment jamais expliqué de façon claire et actionnable. Les contenus sont souvent trop théoriques ou directement orientés “closing client”. Résultat : difficile de se projeter, encore plus de se former efficacement.
Après plusieurs benchmarks d’offres de formation growth marketing, je suis tombée sur une pépite sur Udemy : 6 heures de contenu 100 % axé ciblage, web scraping et enrichissement, notée 4,9/5. Mon objectif était d’apprendre à construire des listes de prospects B2B précises, exploitables, enrichies, le tout en respectant la RGPD.
Et pour une growth marketeuse débutante comme moi, c’était pile ce qu’il me fallait.
Ce que la formation Udemy m’a appris (et ce que j’ai appliqué)
La formation d’Antoine Thoreau sur Udemy a répondu à mes attentes. 6 heures de vidéos à rythme maîtrisable, un formateur expert du sujet (CMO dans une boîte B2B), des cas pratiques à réaliser de son côté, des quiz pour tester ses acquis, et surtout… des fichiers téléchargeables hyper utiles. Notamment un benchmark complet des outils (avec notes, comparaisons, codes promo). Et la cerise sur le gâteau ? Un accès à vie à la formation.
La formation est découpée en trois blocs :
1. Ciblage (60 % du programme)
C’est ici que tout commence. L’intérêt ? Ce n’est pas juste d’extraire. C’est de qualifier la donnée en amont pour limiter les erreurs en aval. Autrement dit, mieux cibler pour moins nettoyer.
J’ai appris à :
- Construire un ICP solide, maîtriser les requêtes Sales Navigator
- Filtrer les bons comptes et les bons prospects
- Affiner mes recherches avec l'outil Parsinator de Pharow et les opérateurs booléens
- Exploiter la fonctionnalité Spotlight pour repérer les signaux faibles et collecter des informations sur les leads potentiels
Le bonus ?
Un template Google Sheet de ciblage sur Sales Navigator partagé par le formateur. En deux mots, il s’agit d’une matrice qui relie les besoins des équipes Commerciales et les requêtes correspondantes sur Sales Navigator. Chaque besoin possède un ID associé qui permet ensuite de tracker les différentes campagnes, d’identifier la ventilation des canaux marketing, la conversion en rendez-vous clients et donc de déterminer leur ROI.
C’est hyper intéressant de découvrir un usage concret de pilotage interne au sein d’une start-up.
Petit tip marquant : toujours analyser la dernière page des résultats des données LinkedIn pour juger de la qualité du ciblage. Si 99% matchent, le reste suit. Sinon, revoyez vos filtres.
2. Scraping (30 % du contenu)
Là, on passe en mode “mains dans le cambouis”. L’objectif ? Extraire des données B2B de prospects depuis des pages web, des annuaires, ou LinkedIn, en utilisant des outils no-code. Pour développer des scripts “maison”, ce sera pour une prochaine fois.
Au programme :
- Initiation au scraping de données via des extensions Chrome (Instant Data Scraper, Pline by Grespr)
- Décryptage des limitations techniques : pagination, éléments dynamiques, click-to-expand
- Revue des types de scraping : web scraping, scraping d’annuaires, scraping des données LinkedIn, scraping via API mais aussi fichiers payants.
- Mais surtout : point complet sur la légalité. Ce n’est pas parce qu’on peut scraper qu’on doit le faire n’importe comment.
D’un point de vue légal, la législation française tolère le web scraping sous réserve de certaines conditions strictes. La CNIL, par exemple, rappelle que la collecte de données doit être légitime, proportionnée, et respecter les droits des personnes concernées (droit d’opposition, d’accès, de suppression). L’article 6 du RGPD encadre les bases légales du traitement.
De plus, capturer des informations des sites dont les CGU interdisent explicitement l’extraction automatisée de données, comme LinkedIn (euh….🫢), constitue une violation contractuelle, voire un acte de concurrence déloyale selon certains avocats spécialisés.
En résumé : scraper oui, mais en connaissance de cause. Mieux vaut privilégier des sources publiques sans restriction ou obtenir un consentement explicite.
Cas pratique : ce que j’ai appris en testant les outils de web scraping
Pour mettre en pratique mes apprentissages, j’ai testé deux outils gratuits : Pline (by Grespr) et Instant Data Scraper. Objectif : extraire des données sur des sites web comme Doctolib, l’annuaire du service public et societe.com. Spoiler : les deux s’en sortent très bien, mais Pline offre quelques avantages notables.
Pourquoi j’ai préféré Pline ?
- Une interface claire et ergonomique
- La possibilité de personnaliser les données collectées (enfin pas vraiment en version gratuite…)
- Un système de templates de workflow très utile pour automatiser ses actions. Dans mon cas, j'avais déjà scrappé Doctolib avec l'outil, qui m'a automatiquement suggéré le workflow associé.
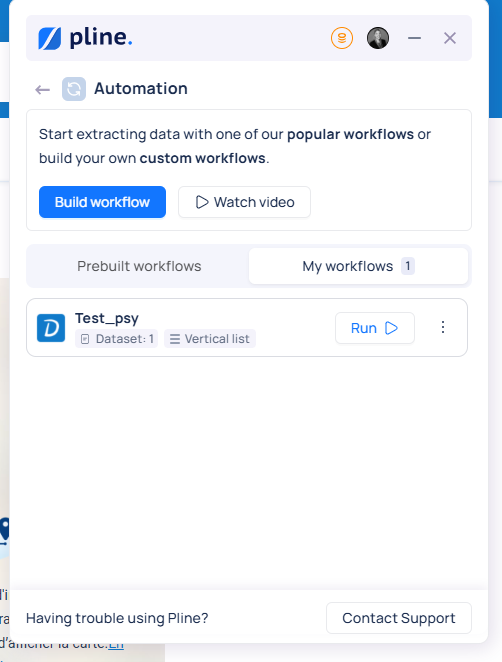
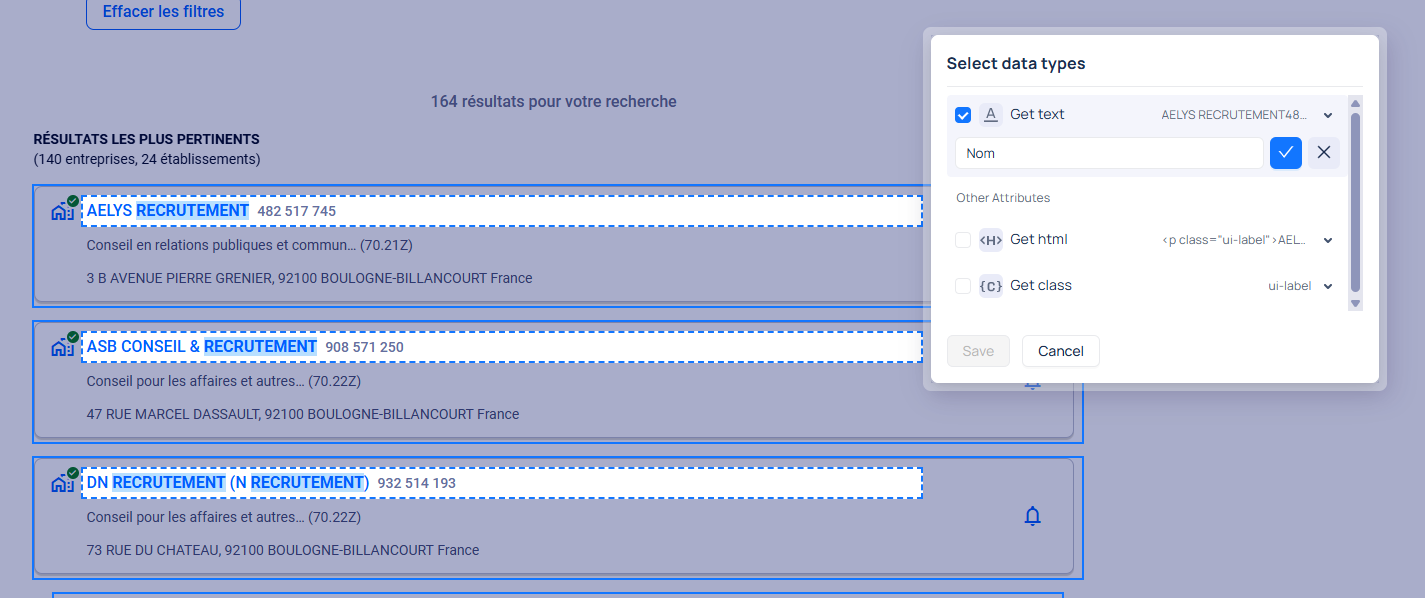
Deux méthodes d’extraction sont proposées, mais la différence principale réside dans la gestion de la pagination. Très utile pour scraper au-delà de la première page de résultats.
Une fois la page ciblée :
- On définit une zone de données (“Grouping”, à ‘l’instar d’un div block)
- On précise les éléments à extraire (nom, lien, class…)
- On peut activer un système de pagination pour élargir le périmètre

⚠️ Limite de la version gratuite : impossible de capturer les informations des pages internes.
Dommage, surtout quand on veut enrichir sa base. Un ancien screencast de ma formation Udemy montre que cela était possible auparavant.
Côté Instant Data Scraper ?
C’est l’outil parfait pour les débutants : vous ouvrez l’extension, vous lancez l’extraction puis vous téléchargez. Rapide et sans friction, mais moins personnalisable.
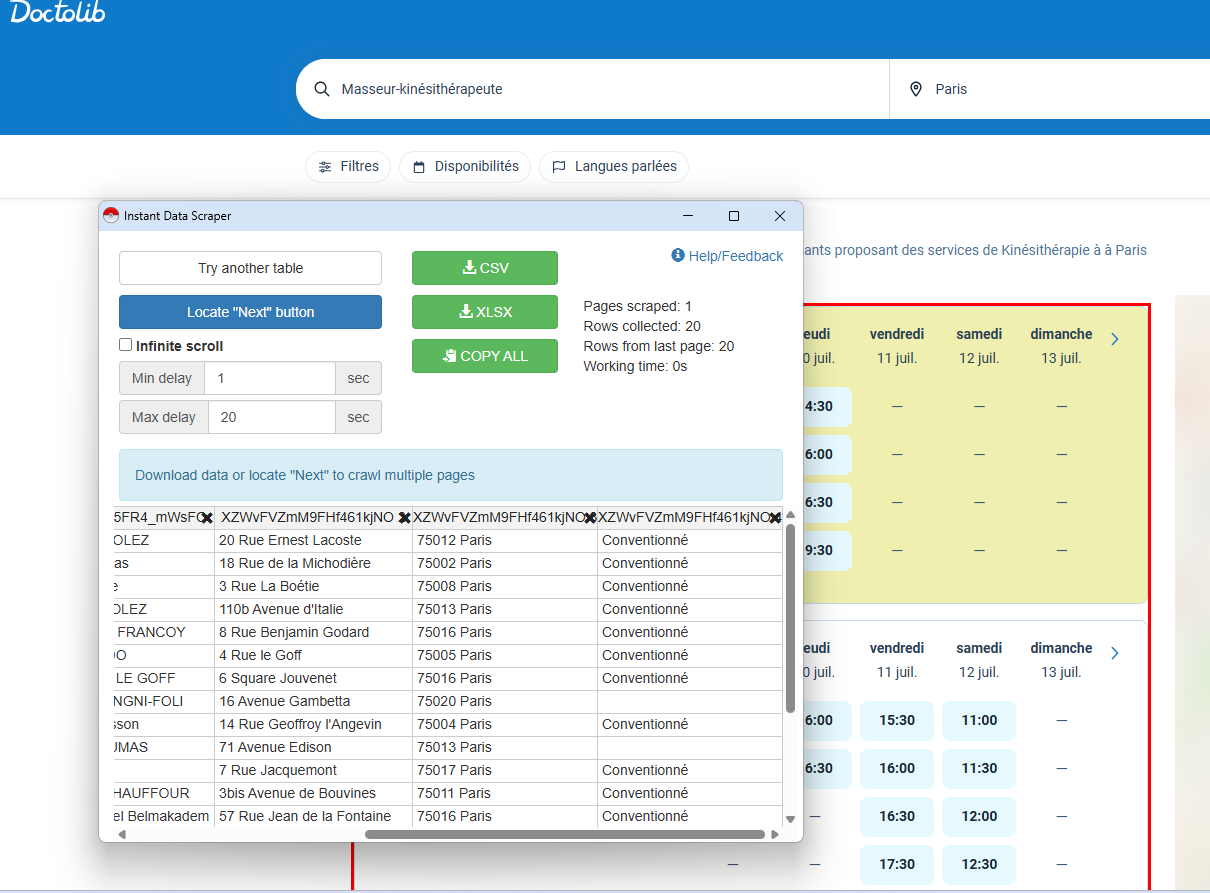
Je précise que le web scraping est ici utilisé de manière responsable, en respectant les conditions d’accès.
3. Nettoyage, enrichissement et usage de la donnée (10 %)
Une fois les données collectées, il faut les rendre exploitables. Et c’est une autre paire de manches.
- Nettoyer une base de données de prospects B2B : formatage, dédoublonnage, gestion des catch-all, suppression des spam-traps
- Tester la validité des emails via Debounce ou ZeroBounce
- Enrichir les leads avec des infos complémentaires grâce à Dropcontact, Clearbit ou Captain Data
Le formateur partage également des conseils de gestion des données, notamment sur l’intégration dans un CRM et la stratégie de campagnes d’outbound.
Cas pratique : enrichissement de leads avec Dropcontact
Avant de lancer une campagne via Dropcontact, assurez-vous de disposer de quatre informations clés par contact :
- le nom
- le prénom
- le nom de l’entreprise
- le lien LinkedIn du profil.
Ces informations peuvent déjà se trouver dans votre CRM de manière structurée.
Pour tester l’outil, j’ai enrichi les données de trois personnes interviewées. Ces leads avaient déjà été traités avec La Growth Machine. Voici ce que la comparaison m’a appris.
La Growth Machine : plus orientée "profil"
- 70 % d’emails personnels retrouvés
- 0 % de correspondance avec les emails pros fournis par Dropcontact,
- Enrichissement très complet sur le profil LinkedIn (bio, intitulé de poste, etc.)
- Accès à l’historique des échanges avec chaque lead (pas de l’enrichissement mais très utile).
Dropcontact : la force des données d’entreprise
- Plus efficace sur les adresses email professionnelles (plus cohérentes, plus fiables)
- Informations complémentaires sur l’entreprise :
- Nom du responsable légal
- Code NAF
- Numéro SIREN
- Adresse du siège social
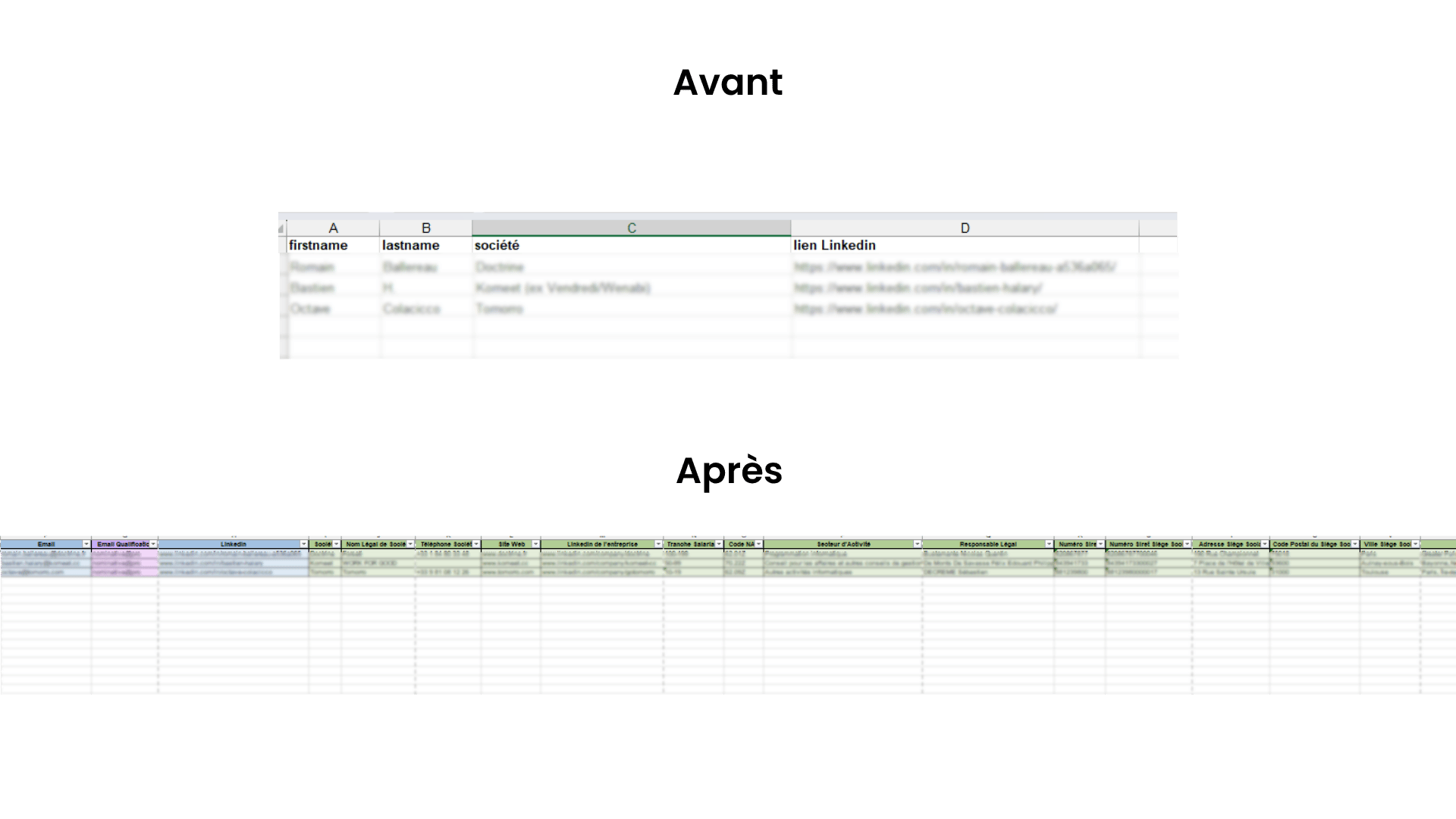
Conclusion : pour un enrichissement vraiment complet, le mieux reste de croiser les deux sources.
L’un vous donne une vision fine du profil ; l’autre vous alimente en données corporate. Ensemble, ils maximisent la qualité de vos fichiers.
Pourquoi je recommande cette formation ?
J’ai particulièrement apprécié la pédagogie : le formateur ne se contente pas de dérouler un tuto technique. Il partage aussi ses erreurs, ses itérations, ses logiques métier. Et franchement, pour une growth marketeuse débutante, c’est de l’or.
Au final, j’ai pu tester des outils concrets comme Sales Navigator, Dropcontact, Grespr, Instant Data Scraper, Debounce ou encore Pharow. Et surtout, comprendre quand et pourquoi les utiliser.
Chaque outil est présenté dans un contexte avec des exemples de données traitées concrètement. Autant d’informations utiles à injecter dans votre CRM pour segmenter plus finement vos leads.
Et tout ça, à 30 €, c’est probablement le meilleur ROI de ma reconversion jusqu’ici !
Les outils testés : ce qui a marché… et ce qui m’a frustrée
J’ai testé 7 outils de web scraping en tout. Tous en version freemium ou via un compte d’essai gratuit. Un choix assumé : je voulais expérimenter sans exploser mon budget.
Mon cas d’usage : cibler, scraper pour interviewer des experts du Growth
En parallèle de cette formation, je souhaitais mener une enquête terrain auprès d’experts du Growth pour m’immerger dans leur quotidien. J’ai donc décidé de fusionner mon besoin avec un cas pratique concret de mise en application : tester des outils de scraping, construire une séquence, bref créer ma propre campagne LinkedIn de prospection, et voir ce que ça donnait.
Un ciblage correct, c’est 50 % du travail.
J’ai utilisé Sales Navigator, en version d’essai, pour segmenter efficacement mes cibles. Mon ICP (Ideal Customer Profile) était défini : professionnels du growth avec au moins deux ans d’expérience, travaillant dans des start-ups ou scale-ups B2B et situés en France métropolitaine (je ne voulais pas avoir uniquement la vision parisienne).
Comment j’ai fait pour me renseigner ?
Déformation professionnelle oblige, je suis allée sur Welcome to the Jungle. J’ai identifié les différentes entreprises qui recrutaient des postes en Growth Marketing ou Growth Hacking. J’ai ensuite consulté leur page entreprise LinkedIn pour matcher les informations avec les critères de requête. Cela m’a notamment permis de trouver des patterns dans les secteurs d’activités.
Requête Sales Navigator : mon processus en 3 étapes pour partir sur de bonnes bases
Ma méthode concrète pour filtrer les bons profils, pas à pas :
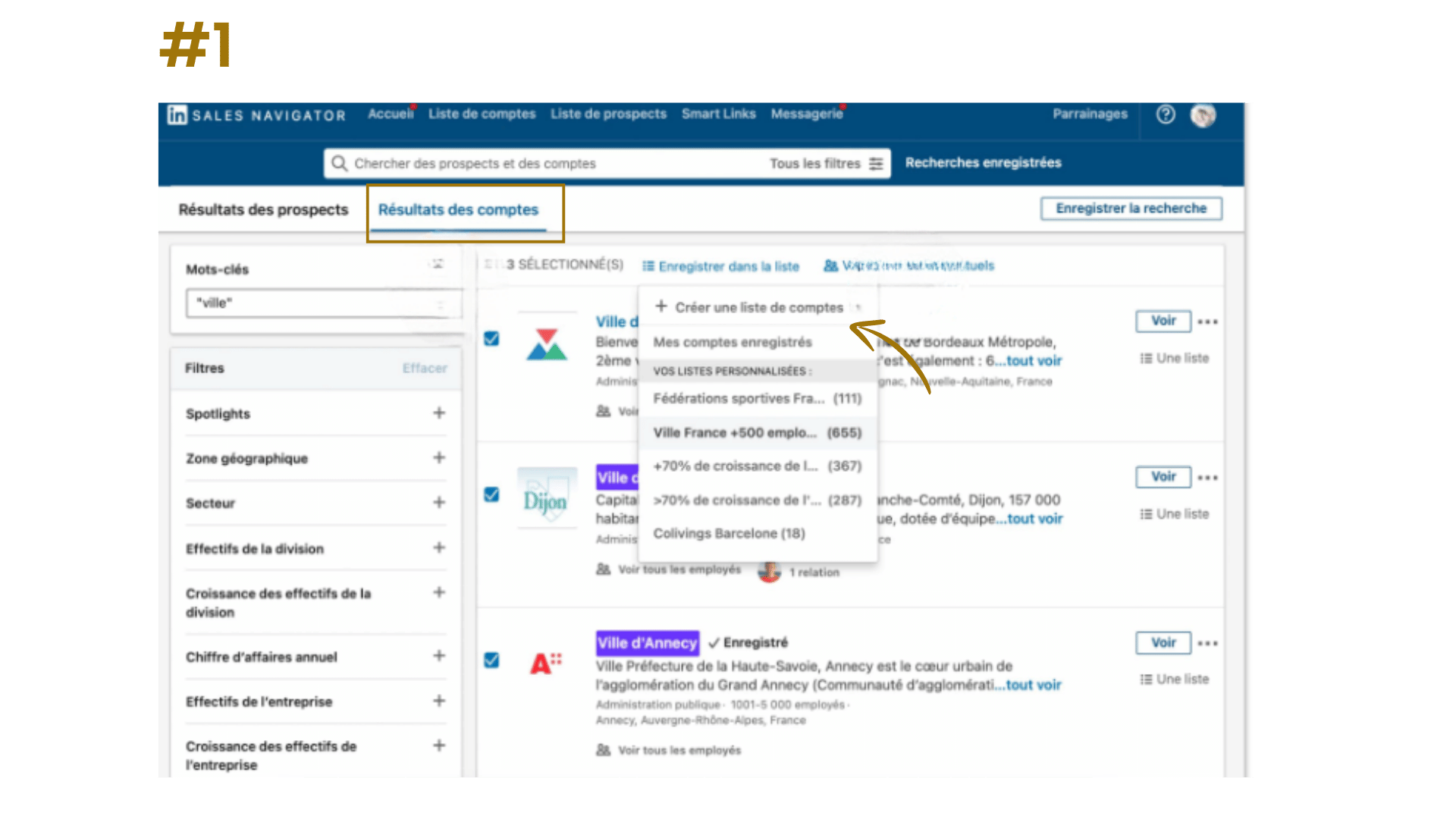
Etape 1 : définir les critères d’entreprises (filtres de comptes)
Avant de sélectionner les bonnes personnes, il faut identifier les bonnes structures. J’ai donc commencé par utiliser les filtres avancés sur les comptes (c’est-à-dire les entreprises).
Voici les critères que j’ai appliqués :
- Effectif total de l’entreprise : entre 11 et 250 salariés → pour rester dans l’univers start-up / scale-up
- Localisation du siège : France métropolitaine → je ne voulais pas une vision uniquement parisienne)
- Effectif de la division “Marketing” : entre 2 et 10 → pour éviter les boîtes où le growth est inexistant ou trop dilué
- Secteurs d’activité :
- Produits logiciels informatiques pour mobiles
- Produits logiciels informatiques pour ordinateurs
- Développement de logiciels
- Développement de logiciels personnalisés de systèmes informatiques
- Produits logiciels intégrés

J’ai aussi testé des secteurs comme “Médias audio et vidéo en ligne”, “Services de relations publiques et communications” et “Services de marketing, mais trop d’entreprises hors cible apparaissaient.
💡 Astuce : commencez toujours par filtrer les entreprises. Cela vous permettra d’avoir une base solide avant d’attaquer les prospects eux-mêmes.
Étape 2 : créer une liste de comptes
Une fois les bons comptes identifiés, je les ai ajoutés à une liste personnalisée. Cela me permet de les retrouver facilement et de les réutiliser dans la prochaine étape.
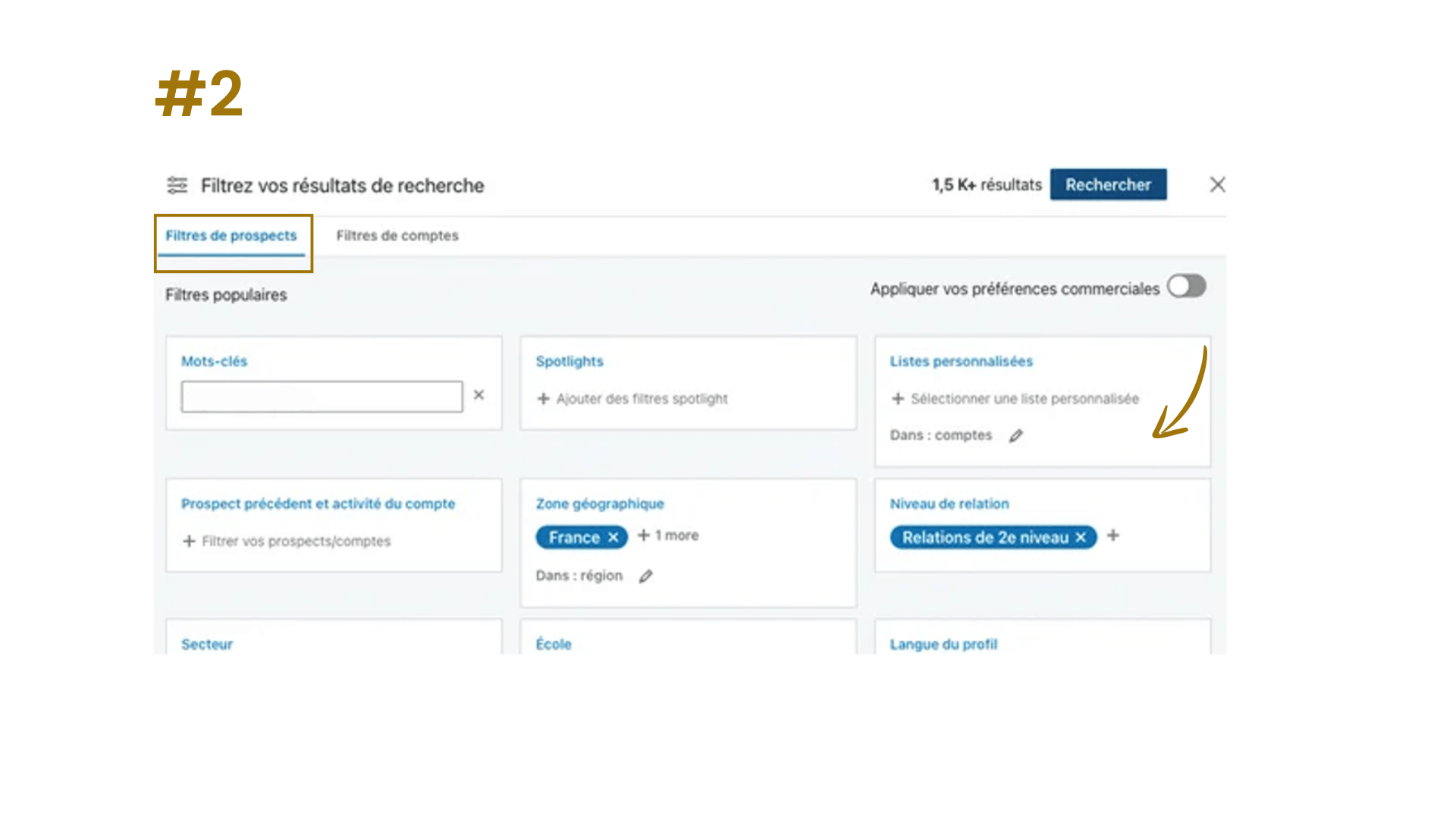
Étape 3 : affiner les critères des prospects
Ensuite, direction l’onglet “Filtres de prospects”. J’ai filtré tous les contacts issus uniquement des comptes ajoutés précédemment, et j’ai affiné selon :
- Expérience : plus de 2 ans → pour éviter les étudiants et jeunes diplômés
- Intitulés de poste dans le growth marketing (filtrés ensuite avec une requête booléenne que je détaille dans la section dédiée)
Ciblage des intitulés de poste : comment j’ai utilisé la recherche booléenne pour affiner ma base de données
Une fois mon ICP défini, j’ai voulu trouver les bons intitulés de poste, même ceux mal catégorisés ou mal orthographiés. Pour cela, j’ai utilisé la recherche booléenne, via l’outil gratuit Parsinator de Pharow, qui m’a permis de générer une requête complète et cohérente.
C’est quoi une recherche booléenne ?
C’est une formulation de requête logique qui combine plusieurs mots-clés à l’aide d’opérateurs. Concrètement, cela permet :
- de cibler large sans passer à côté d’intitulés alternatifs (avec
OR) - de croiser des critères précis (avec
AND) - d’exclure certains utilisateurs (avec
NOT) - d’éviter les faux positifs grâce aux guillemets et parenthèses. Autrement dit, les profils qui semblent correspondre, mais ne correspondent pas réellement à mon but.
Mode d’emploi des opérateurs booléens
Voici les principaux opérateurs que j’ai utilisés (et que vous pouvez copier-coller dans vos propres requêtes) :
Bonnes pratiques à suivre
- Lister tous les intitulés possibles, en français et en anglais :
"growth manager" OR "responsable acquisition digitale" OR "user acquisition manager"… - Penser aux variantes féminines et masculines :
"directeur marketing" OR "directrice marketing" - Inclure les acronymes et leur version longue :
"DSI" OR "Directeur des systèmes d'information" OR "CIO" - Prioriser les mots-clés univoques et qui se suffisent à eux-mêmes comme
"Salesforce", "ERP", "Hubspot" - Utiliser les guillemets dès qu’un intitulé comporte plusieurs groupes de mots comme
("growth manager" OR "head of growth") AND B2B
Pièges à éviter
- Ne pas fermer les parenthèses → résultat invalide ou incomplet
- Utiliser les opérateurs en minuscule → ils ne seront pas reconnus par LinkedIn
- Chercher des acronymes ambigus seuls : exemple "CDO" qui peut vouloir dire Chief Data Officer, Chief Digital Officer… ou Collateralized Debt Obligation
- Trop restreindre la recherche avec
AND→ risque de passer à côté de profils intéressants
Mon cas concret
Voici un extrait de la requête que j’ai utilisée grâce à Parsinator de Pharow pour cibler les bons profils :
("growth marketing manager" OR "growth manager" OR "responsable marketing acquisition" OR "responsable acquisition digitale" OR "lead generation manager" OR "user acquisition manager" OR "digital acquisition manager" OR "demand generation manager" OR "paid acquisition manager" OR “growth hacker”)
Mais pour optimiser son ciblage, il faut aussi exclure les utilisateurs non pertinents. Pour garantir la cohérence avec mon projet (interviewer des professionnels expérimentés en poste), j’ai mis en place une requête d’exclusion assez robuste, grâce à l’opérateur NOT et à un bon usage des parenthèses.
Voici un extrait :
NOT ("consultant" OR "étudiant" OR "enseignant" OR "formateur" OR "formatrice" OR "alternant" OR "stagiaire" OR "professeur" OR "apprenti" OR "prof" OR "Msc" OR "Bachelor" OR "MBA" OR "association" OR "freelance" OR "founder" OR "CEO" OR "co-founder" OR "assistant" OR "assistante" OR "adjoint" OR "adjointe" OR "secrétaire" OR "secretaire" OR ("maître" AND "conférence"))
Cette requête m’a permis d’écarter les membres en formation, juniors, formateurs, assistants ou dirigeants qui ne correspondaient pas à mon ICP (Ideal Customer Profile). L’exclusion des termes ambigus ou trop génériques m’a aussi évité de “polluer” ma base de données avec des profils hors sujet.
💡 Astuce : cette étape d'exclusion est souvent négligée, mais elle augmente drastiquement la qualité de votre audience de leads.
Autre critère important : ne sélectionner que des profils LinkedIn en connexion de 2e degré. C’est une astuce simple mais puissante pour maximiser les chances d’acceptation des demandes de connexion : les “amis de mes amis” sont souvent plus enclins à accepter une invitation.
Ce processus m’a permis de construire une base ciblée de 100 profils LinkedIn qualifiés, en réduisant les faux positifs et en couvrant un maximum de variations.
Passer du ciblage à l’activation : place à la prospection en conditions réelles
Une fois mes données prêtes, je suis passée à l’étape suivante : l’automatisation de ma prospection sur LinkedIn. Objectif : comparer deux outils incontournables du moment La Growth Machine et Waalaxy et comprendre leurs vraies forces (et limites) en conditions réelles.
A noter que j’aurais pu utiliser l’outil de scraping LinkedIn aussi souvent recommandé, à savoir PhantomBuster.
Je partage mes tests, mes séquences et mes retours d’expérience 👇
À lire si vous hésitez entre les deux… ou si vous voulez éviter quelques galères.
La stack growth du débutant
Voici les 6 outils essentiels pour se lancer dans le scraping, le ciblage et l’enrichissement B2B. Testés et validés en conditions réelles.
💡 Astuce : Ces outils fonctionnent bien en version freemium (mais parfois c’est frustrant) ou avec des comptes d’essai. Idéal pour apprendre sans exploser son budget.
Sans oublier un bon CRM pour automatiser la création de fiches contacts et transformer ces données en leviers d’action.
Mon avis sur le ciblage, le scraping et l’enrichissement : est-ce fait pour moi ?
Franchement ? Oui.
Je m’attendais à quelque chose de plus technique, plus opaque, voire franchement rebutant. En réalité, le scraping B2B et l’enrichissement de données, une fois les bons outils identifiés, relèvent surtout de la logique et de la rigueur. Ce n’est pas un domaine réservé aux devs ou aux ingénieurs. Il faut tester, comprendre, itérer. Et surtout : respecter la loi.
Le scraping, bien utilisé, devient un accélérateur de génération de leads, surtout en outbound B2B.
Et l’enrichissement ? C’est le maillon-clé pour ne pas prospecter dans le vide. Des données propres, validées, enrichies, c’est ce qui permet d’améliorer le taux de conversion, de comprendre comment un prospect devient un lead qualifié et d’industrialiser ses démarches de prospection.
Ma seule limite actuelle : je n’ai pas encore connecté tout ça à une campagne complète (type cold emailing ou LinkedIn Ads) ni mis en place des processus automatisés. Je maîtrise les briques du ciblage et de la collecte, mais je n’ai pas encore de recul sur l’activation. Ce sera l’étape suivante. Et autant dire que j’ai hâte de passer de la collecte à l’action.
J’ai mis les mains dans le cambouis. Et franchement ? J’ai adoré ça.
Le ciblage, le scraping, l’enrichissement... Ce ne sont pas des gros mots. Ce sont des briques stratégiques qu’on peut apprendre, tester, et maîtriser. Même avec un background marketing “classique”. Même sans être dev.
Est-ce que je suis prête à construire une machine d’acquisition complète ? Pas encore.
Mais je sais poser les fondations. Et quand on est en reconversion, c’est déjà une sacrée victoire.
Ce qu'il faut retenir
- Un bon ciblage, c’est 50 % du succès. Et ça se construit avec méthode, pas au doigt mouillé.
- Le web scraping n’est pas réservé aux développeurs. Avec les bons outils no-code, on peut extraire des données B2B comme un pro.
- Oui, le scraping est légal… dans un cadre strict. Lisez les CGU des sites web, respectez la CNIL, restez RGPD-friendly.
- Ne sous-estimez jamais l'enrichissement des données : c’est ce qui permet d’avoir une base de données propre, exploitable et conditionne vos conversions.
- Ne vous arrêtez pas à la théorie. Testez, ratez, ajustez. C’est là que commence l’apprentissage.
A qui s'adresse cet article ?
Quels outils ont été utilisés ?
Articles similaires


A propos de l'auteur

Après 12 ans en marketing RH, Célia a décidé de prendre un nouveau tournant et de se reconvertir dans le Growth Marketing.
Formations, certifications et expérimentations terrain : elle a développé ses compétences et est maintenant prête à se lancer sur le marché du travail.
👉 Découvrez son parcours


